

数据驱动:腾讯助力自动驾驶落地
最近在某直播平台上学习了苏奎峰老师关于腾讯如何落地自动驾驶的分享,下面我将直播的主要内容进行复盘,来谈一谈腾讯是如何布局自动驾驶的,他们的核心竞争力有哪些?

谈论任何一个新事物之前,我们都会先讨论一下新事物的价值,自动驾驶也不例外。
苏老师在直播一开始并没有直接谈论自动驾驶的价值,而是从产品的角度提出了一个有意思的观点:
任何一个新的产品,只要能够满足以下三点,那么这个新产品就一定有价值。
-
提升效率;
-
降低成本;
-
提升用户体验。
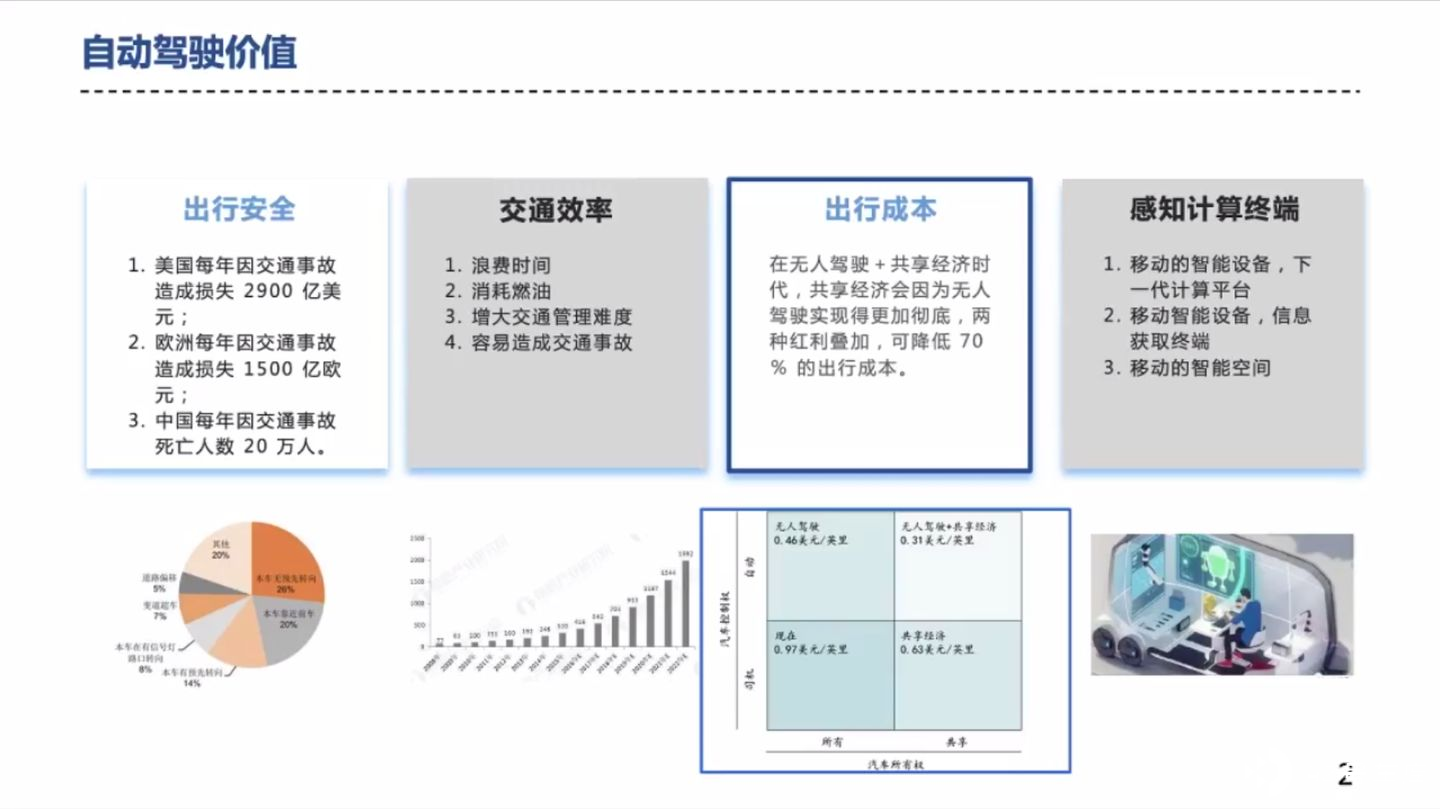
自动驾驶能够提升出行效率、降低出行成本和提升驾乘人员体验,这方面已广泛达成共识,因此自动驾驶这个产品,或者说这项技术肯定是有价值的。
另外,自动驾驶除了在安全、效率、成本方便有较大价值外,还拥有较大的辐射效应。作为一个终端,自动驾驶汽车可以为新基建战略下的 iot、大数据领域的设备,提供基础的数据和服务。
考虑到汽车行业的重资产属性,腾讯作为互联网公司,更愿意发挥其自身的优势,将精力主要聚焦在软件和服务层面。因此有了如下布局:
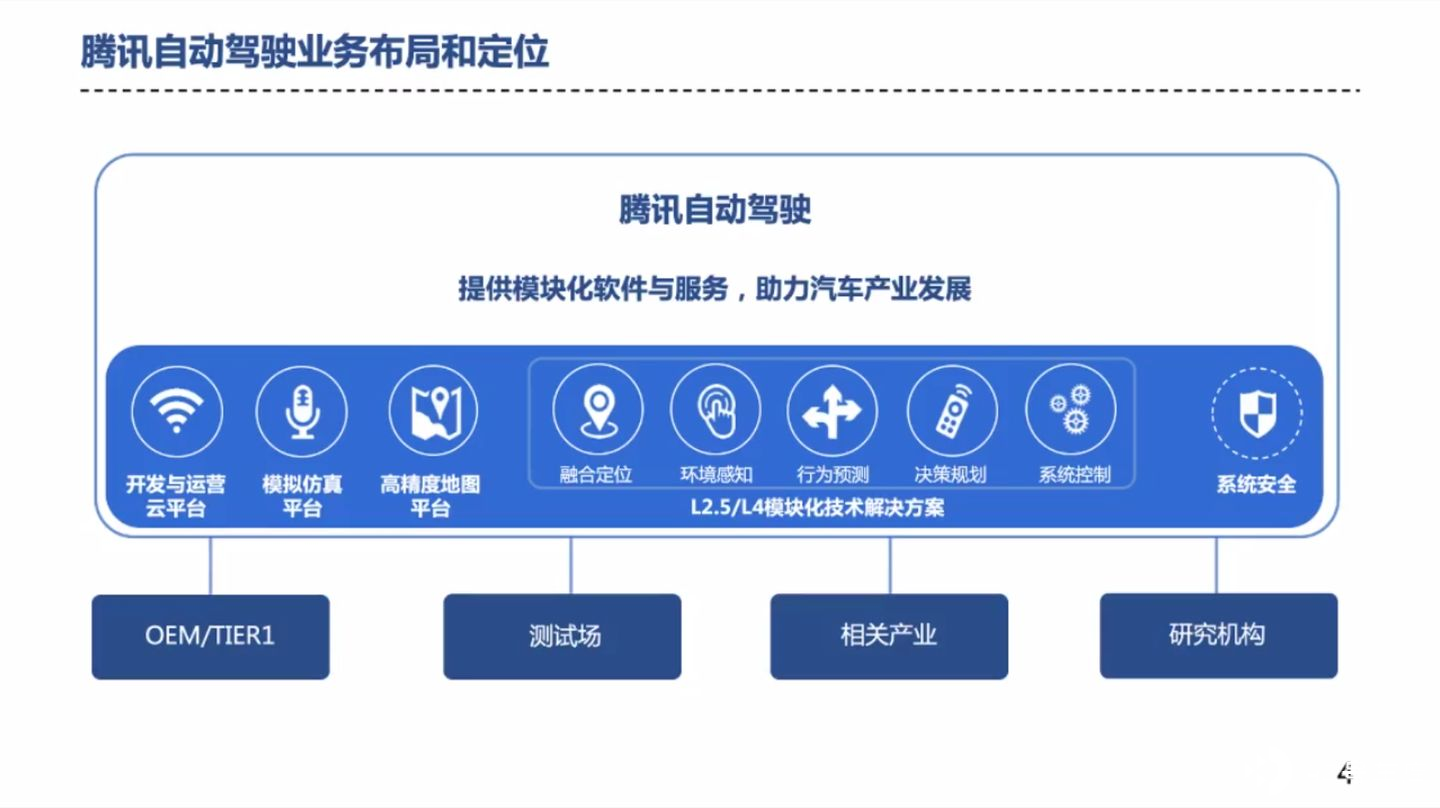
在软件和服务上,腾讯自动驾驶使用了腾讯云平台、模拟仿真平台和高精地图平台,这三个平台都是建立在云端的。车端的解决方案包含了定位、感知、规划、决策、控制的全栈技术。
值得一提的是,在系统安全方面,除了基本的功能安全开发外,腾讯的科恩实验室(曾破解过特斯拉)也会参与进来,保证信息安全。
直播中提到了自动驾驶领域的两大技术路线:模型驱动和数据驱动。
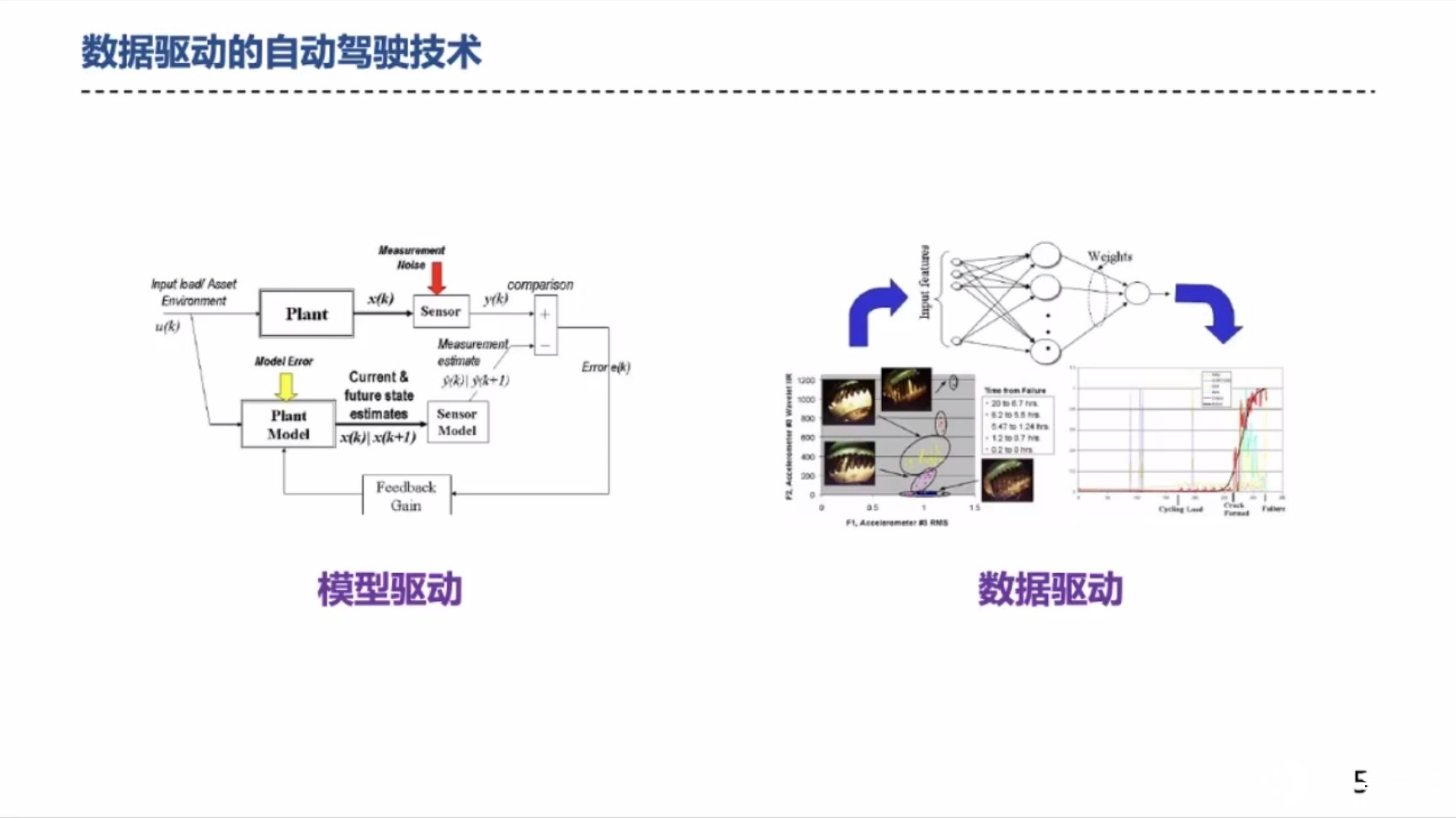
模型驱动,简单来讲,就是基于规则的技术,拥有较好的可解释性。
数据驱动,简单来讲,就是基于机器学习的技术,能够利用大规模的数据使得系统更加稳定和完善。
近几年,数据驱动在自动驾驶的感知、决策等领域表现越来越好,越来越受到青睐和重视。
在感知方面:

数据驱动的系统,相比于模型驱动,能够更好地适应各种不同的天气和路况,检测效果也有一个更大的提升。
基于模型的系统,处理感知问题时,是很难达到理想的效果的。下图为使用基于数据驱动的方法,实现的场景分割。

在决策 / 规划方面:
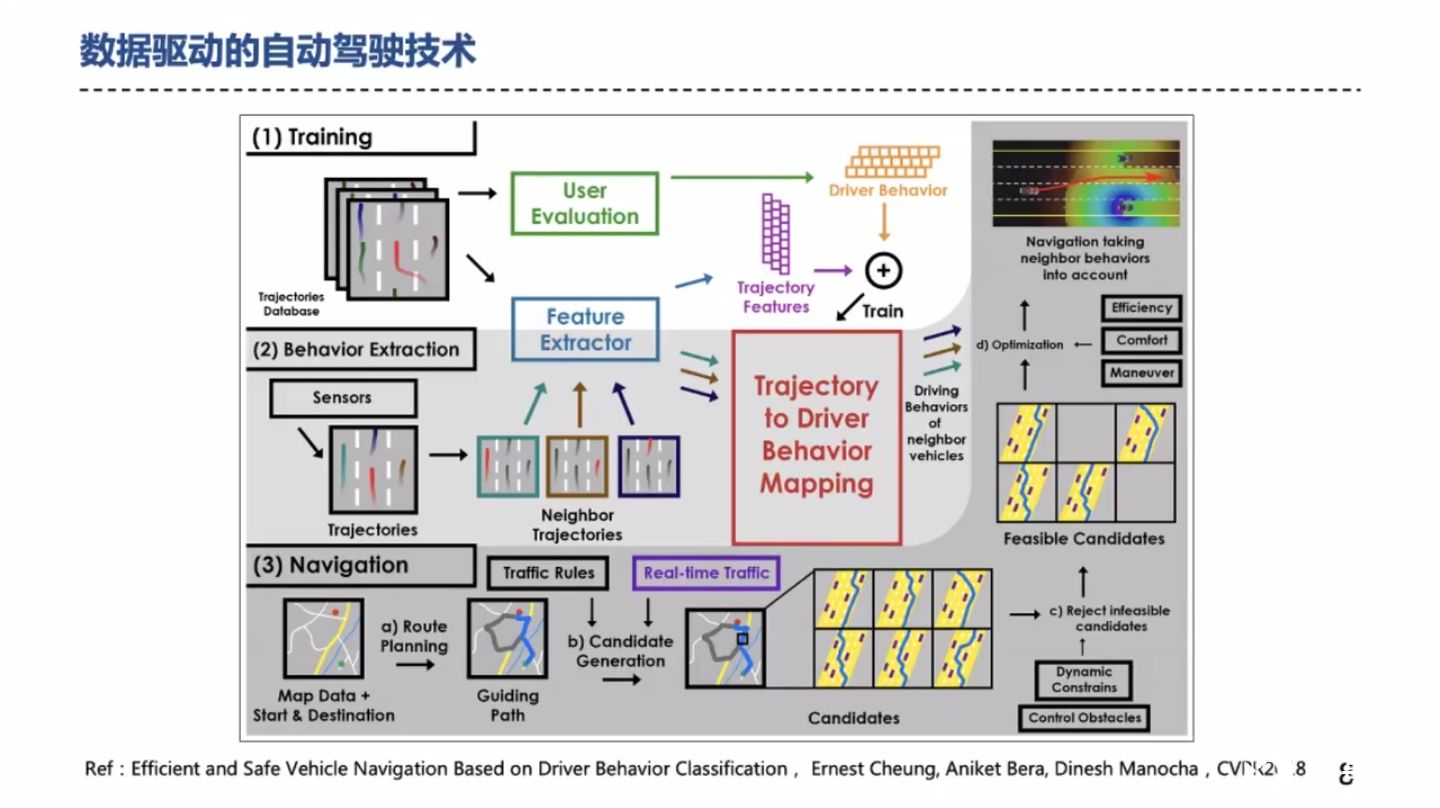
业内还是以模型驱动为主,数据驱动为辅。不过,越来越多的团队开始通过采集驾驶员的行为特征,结合高精地图和导航信息,训练决策规划模型,使系统所做的决策规划更接近人类。
数据驱动的方法不仅适用于决策规划,也同样适用于控制模块。
除了技术开发外,测试验证也是一个很重要的环节。
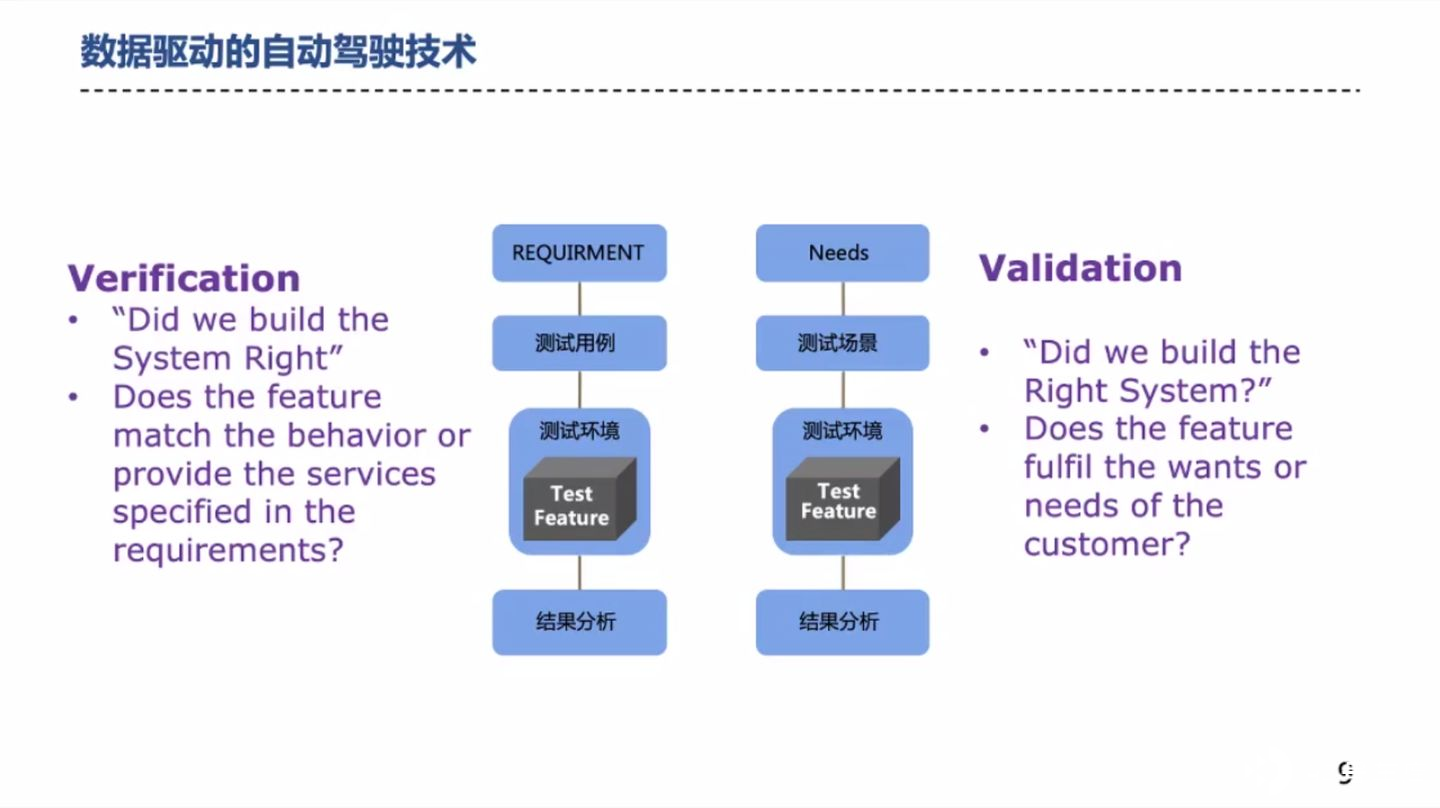
苏老师提到了两大类测试验证方法:Verification 和 Validation。
第一类 Verification,即把系统设计对(Build the system right)。为了实现某种功能而设计的系统,在设计完成后,如果能够顺利通过提前设计好的一些测试用例,则证明 「系统被设计对」了。在自动驾驶分级中,L1 级别的测试,采用 Verification 的做法即可满足。
第二类 Validation,即设计一个对的系统(Build the right system)。很显然,除了需要通过最基本的测试用例外,还要确保系统能够在测试用例之外的场景中,做的足够好。因此 Validation 的测试用例和场景覆盖度都需要极大增加。在自动驾驶分级中,L2 以上级别(即驾驶员脱手)的测试验证,需要采用 Validation 的验证方法,以支持尽可能多的场景。
测试用例可以通过仿真或实车路测的方式进行增加。无论是仿真还是路测都属于数据驱动的范畴。
以上论证,都是为了说明无论是感知、决策、规划、控制,还是最终的测试验证,都是需要大量数据做驱动的。
下来重点来了,腾讯自动驾驶是如何使用数据,实现数据驱动的。
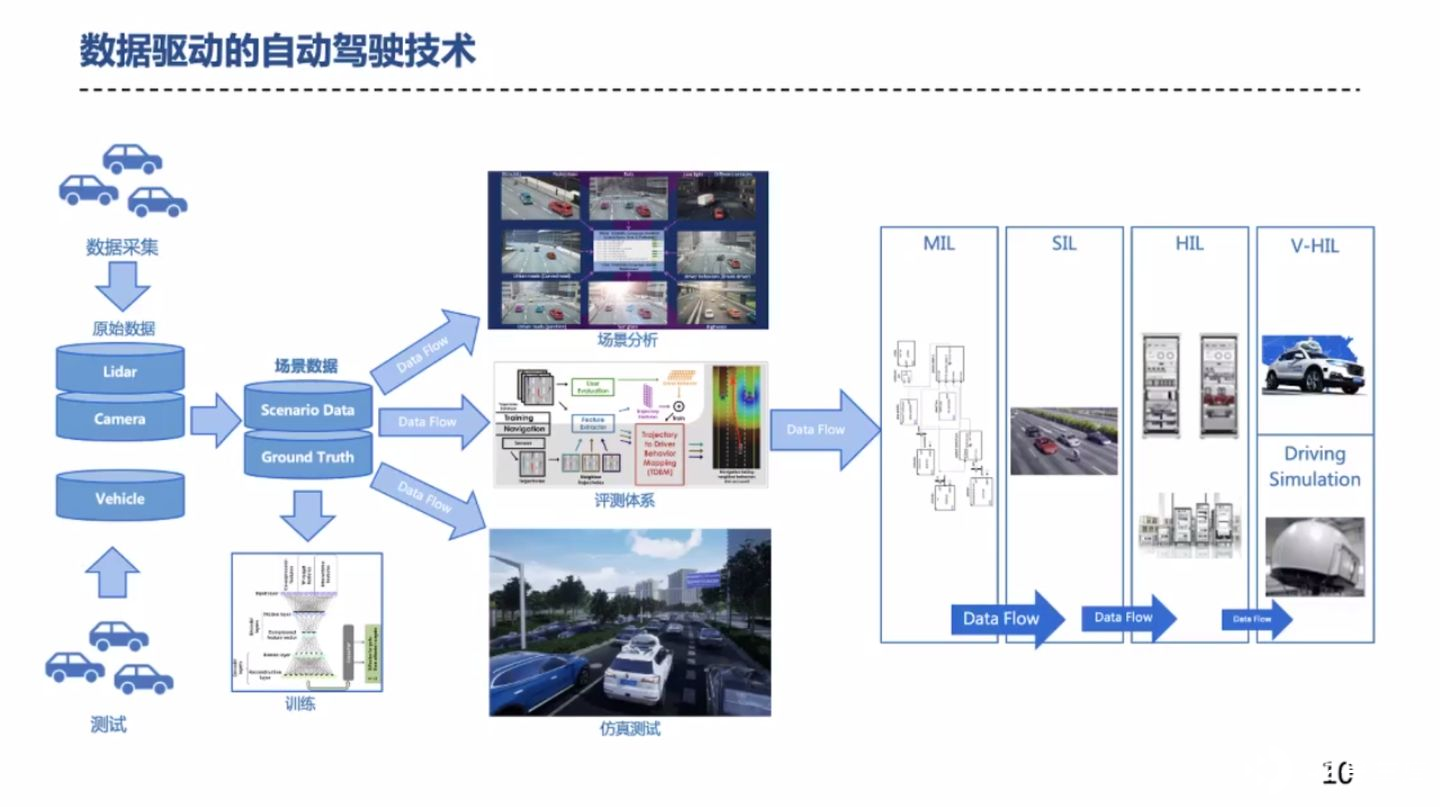
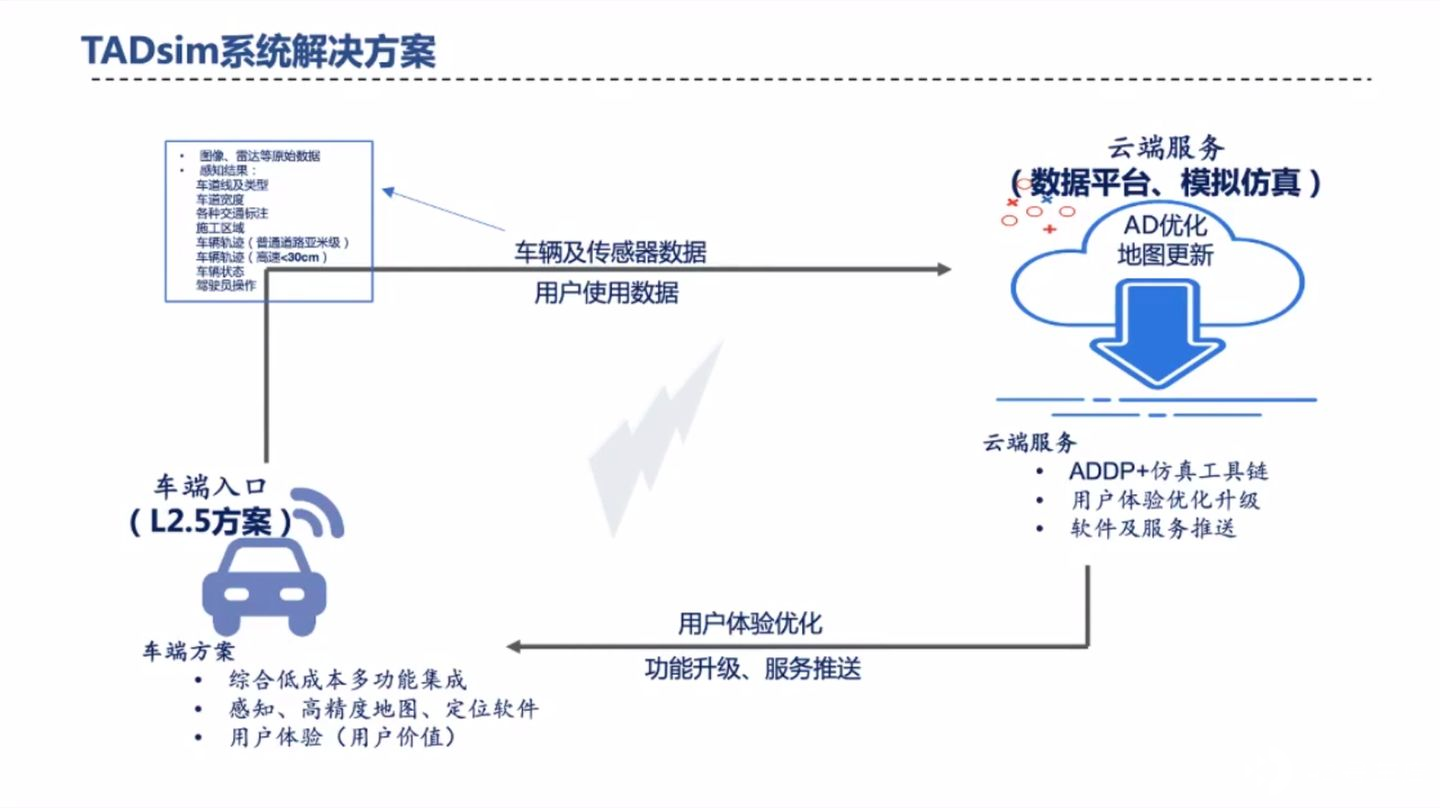
由数据采集和测试积累原始的数据,在标注后应用于模型训练和评测体系,最终将在输入各种在环系统。
腾讯在数据使用方面,与大多数厂商的技术路线差别不大,那腾讯自动驾驶的竞争力在哪呢?
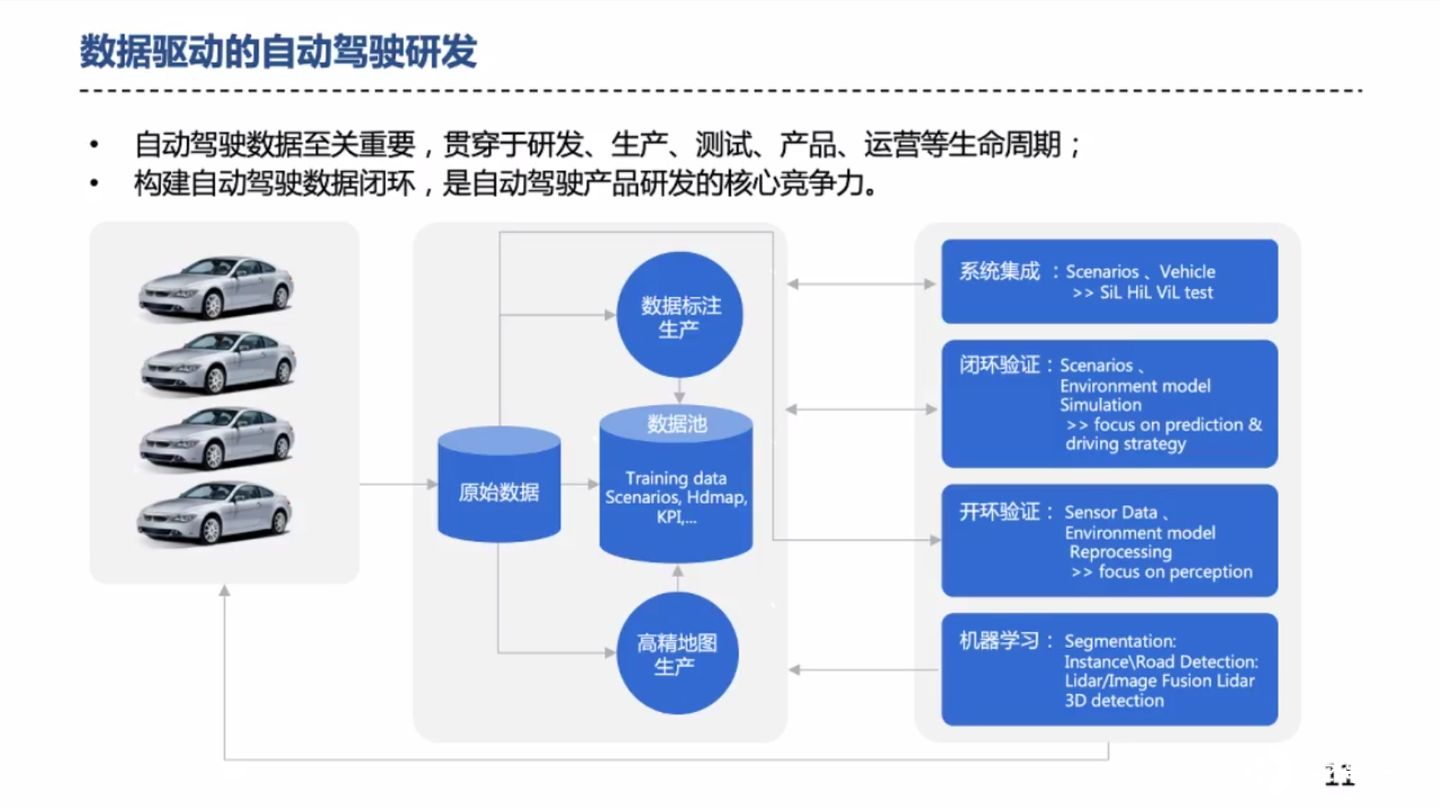
苏老师强调,在未来,自动驾驶算法只占整个自动驾驶产品核心竞争力的很小一部分,构建一个高效的自动驾驶数据闭环,才是自动驾驶产品的主要核心竞争力。数据闭环建立后,如何尽可能地提高数据流转效率和降低数据流转成本,也是一项核心竞争力。
随后苏老师介绍了,腾讯自动驾驶对于数据的详细处理过程,内容如图。
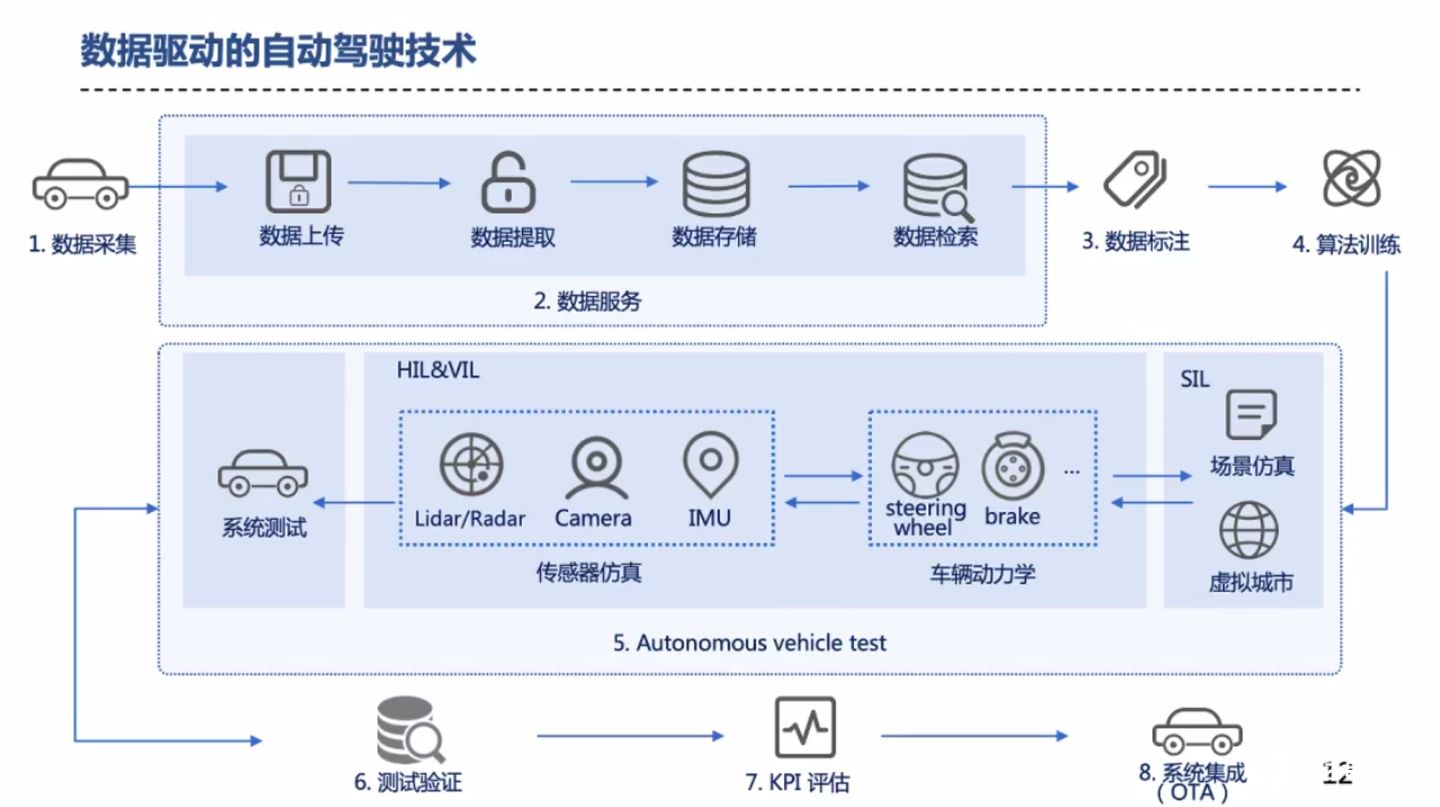
如何利用数据闭环优化算法呢?苏老师举了一个例子。
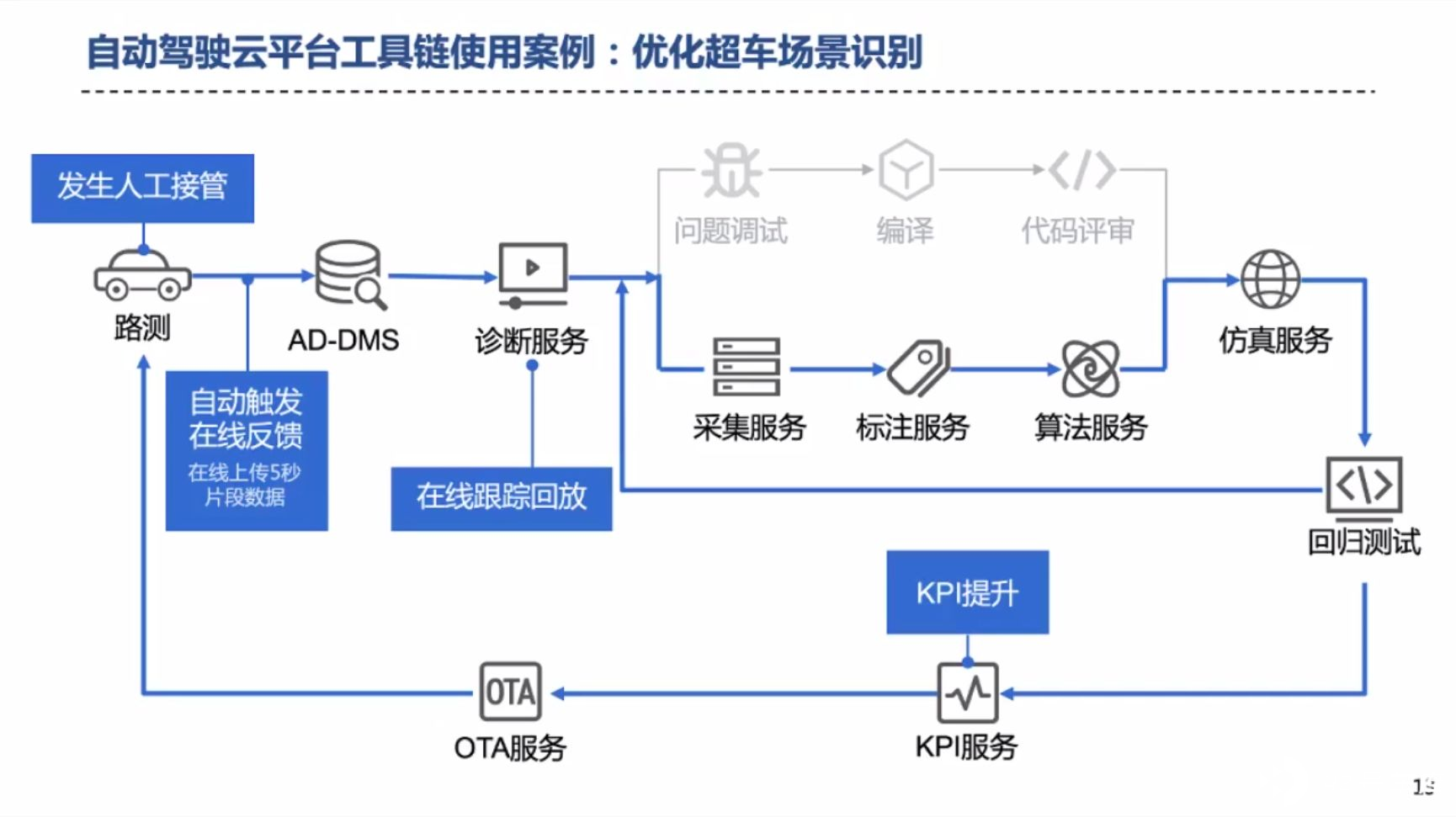
比如,当车端发生了人工接管、或某些车内指标未达标的情况下,车端会将车端一段时间内的数据上传至数据管理系统 AD-DMS(Autonomous Driving Data Management System),随后对数据进行清洗和检索类似数据,当现有数据集还不足以解决车端发生的问题时,则会启动数据的采集服务和标注服务,增加大数据集并重新训模型、测试算法,指标提升或问题解决后,通过 OTA 服务更新至车端。
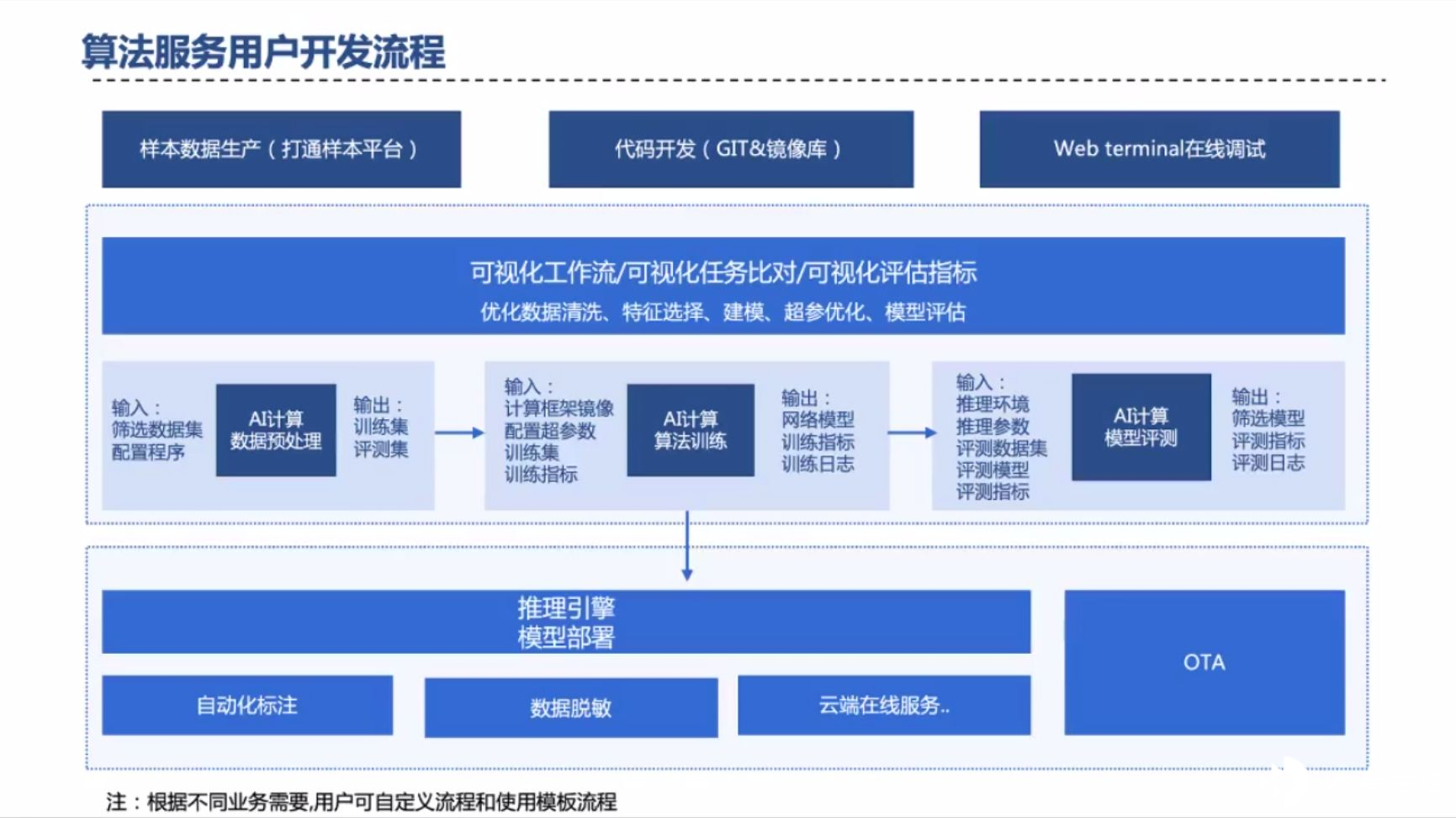
除了数据的闭环,算法服务方面也会有各种开发流程,如下,苏老师并未详细介绍。
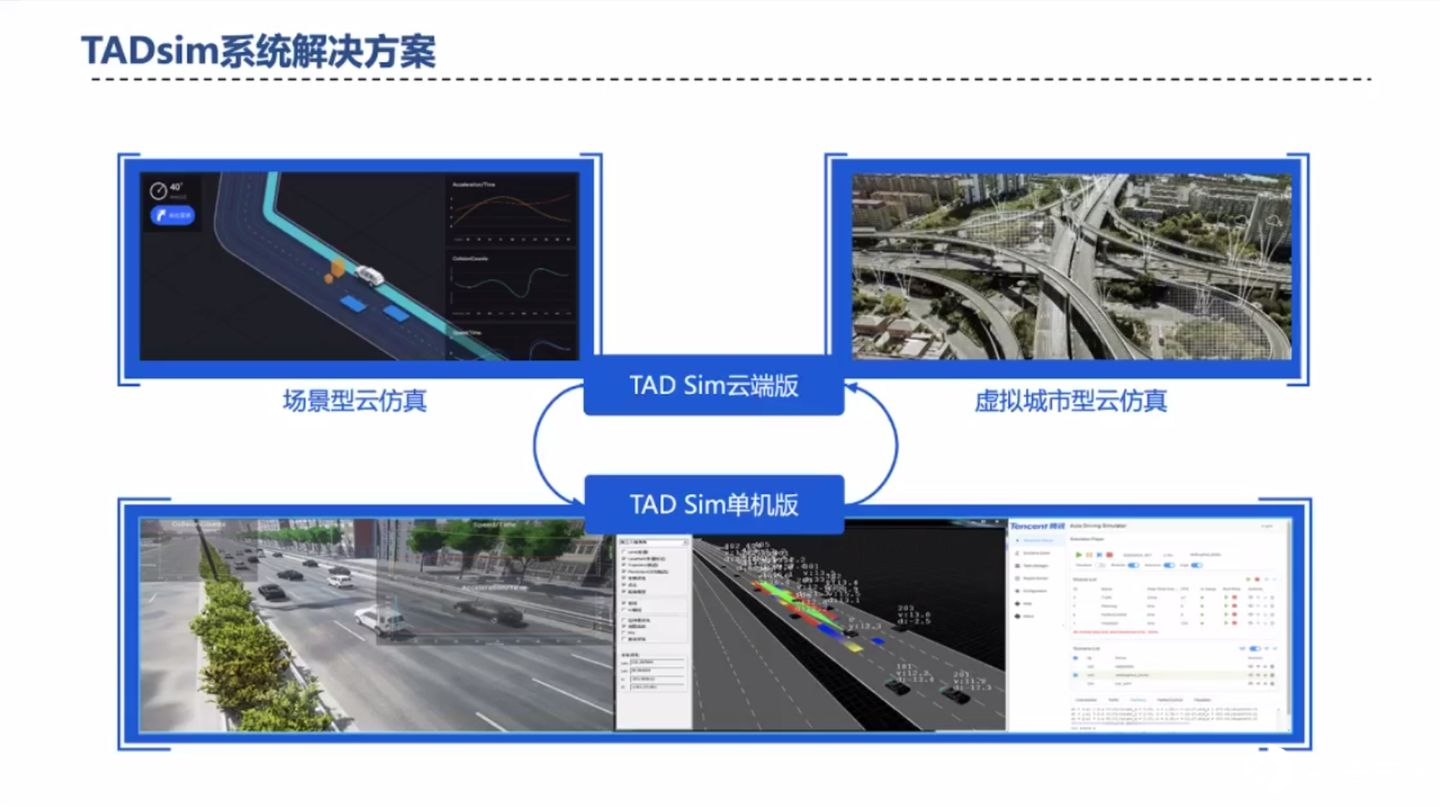
随后,苏老师着重介绍了腾讯的仿真解决方案 TADsim(Tencent Autonomous Driving Simulation)。
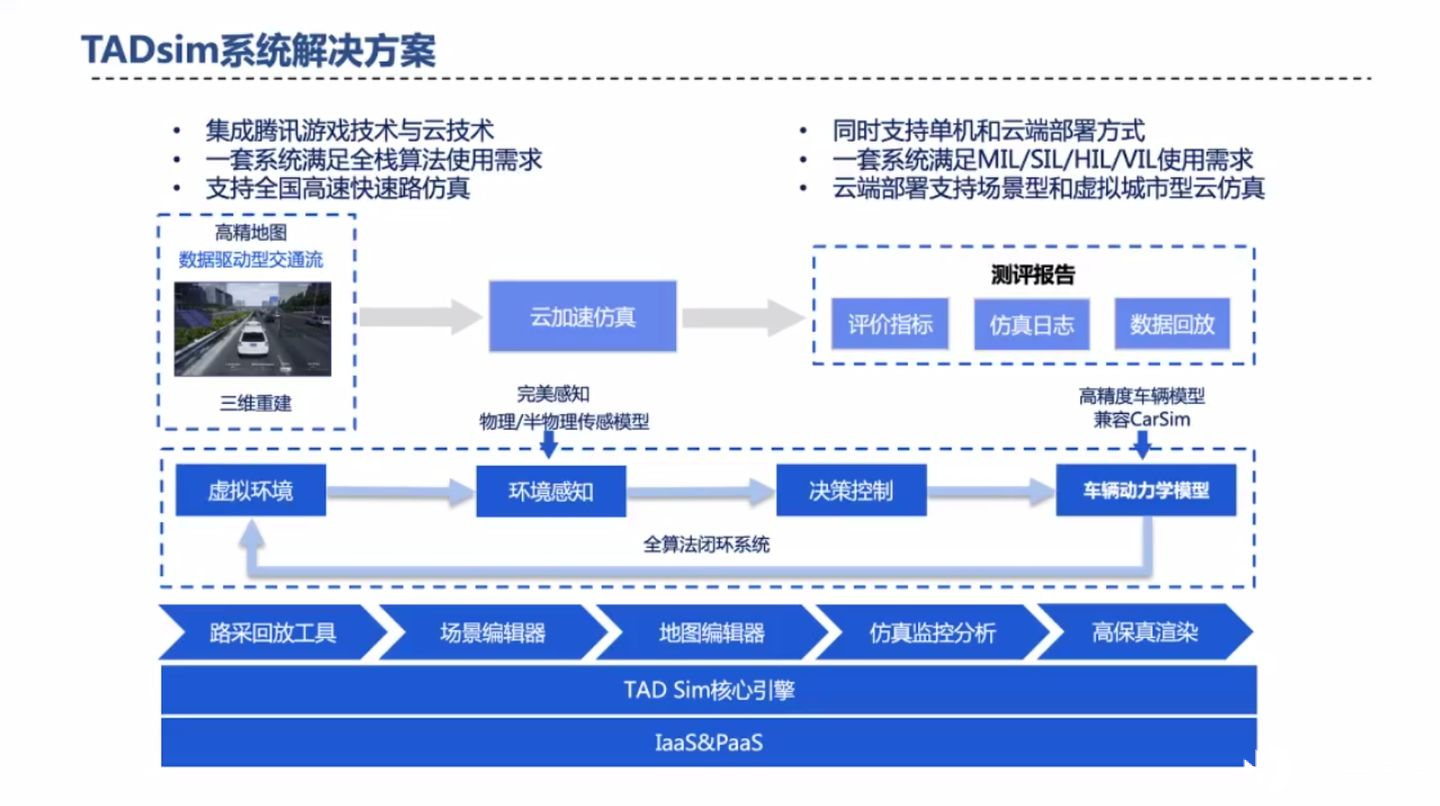
TADsim 可以支持离线单机版和云端版,单机版可以本地查看更加精确的参数,方便工程师调试算法;云端版可以利用虚拟城市生成更多场景,创造更多 Corner-case 以提升算法鲁棒性。
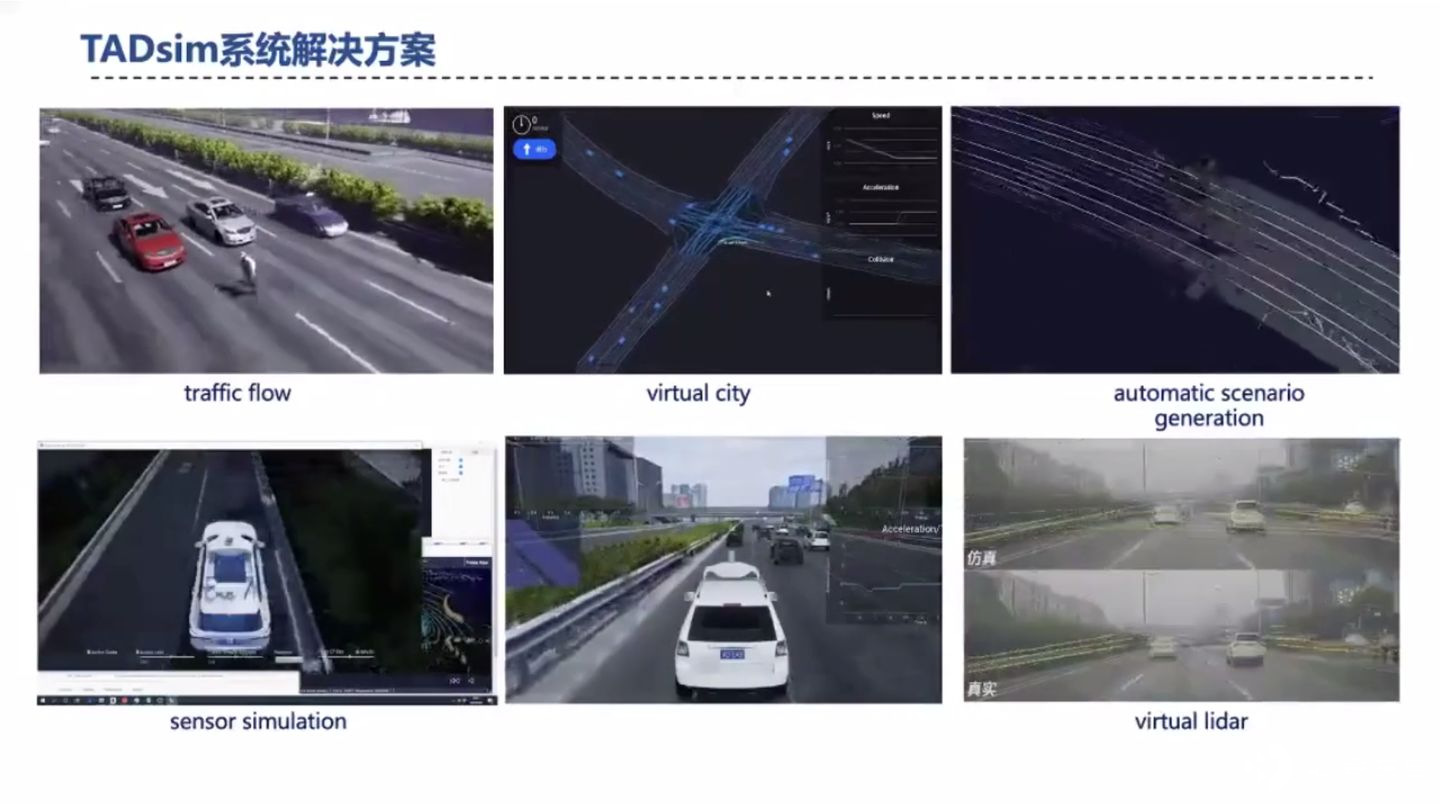
下面展示了 TADsim 生成的各种场景,比如不同的车流、行人场景;传感器的仿真;天气的仿真。
在最后,苏老师再次强调自动驾驶产品的核心竞争力体现在整个数据闭环中的数据流的流动效率和成本,效率越高,成本越低,产品的竞争力越强。有越来越多的 OEM 和自动驾驶创业公司也认识到了这一点。
在 QA 环节,苏老师在回答问题时,抛出了几个观点,在此记录一下:
-
不要生硬地套用某个产品的自动驾驶等级(L1~L5),应更多的关注产品能否解决用户的痛点;
-
腾讯不造车,也不造传感器,仅提供软件服务;
-
腾讯不专注于某一垂直领域(比如 Robotaxi 或无人物流),会将更多精力投入到乘用车领域,利用现有技术,服务好车企。
以上就是苏奎峰老师所分享的数据驱动下的腾讯自动驾驶业务。
个人观点
数据不仅能够完善数据驱动的算法,还有助于生成各种各样的自动驾驶场景,其重要性不仅得到了像腾讯这样的互联网大厂的认同,也同样得到了自动驾驶创业公司和大量 OEM 的认同。
如头部自动驾驶厂商 Waymo 除了在自己的仿真软件 Carcraft 中进行每天的例行测试外,还会派出大规模的车队进行实际的路测,收集数据;Tesla 更是直接通过用户的正常驾驶,获取各种数据。
但到目前为止,国内厂商似乎还没有哪一家自动驾驶厂商,已经做到或有计划做这种大规模的自动驾驶车队,因为数据量小,又没能实现数据的自动化处理,就必然会出现数据采集、标注成本居高不下的问题。
另外,Waymo 和 Tesla 大规模的数据采集都是基于同一套传感器(Waymo 为自研,Tesla 近两代产品都是基于同一套传感器方案)。而腾讯服务不同车厂所获取的数据,其数据来源将来自不同 Tier1 的五花八门的传感器组合,这样的数据其维护成本不低。
在不做传感器的大背景下,如何处理好非同源传感器方案的数据,或许是腾讯正面临的一大挑战。



























