
不是郑小康
关注
环形隧道
2023-08-16

OK,这是 Andrej Karpathy 先发的一条 X:为什么 Mac 跑大模型的表现如此之好?
一个对比,英伟达 A100 内存带宽 1935 GB/s,算力 1248 TOPS,M2 的 Mac 内存带宽 100 GB/s,算力 7 TFLOPS,两者算力差 200 倍,但内存带宽只差 20 倍。
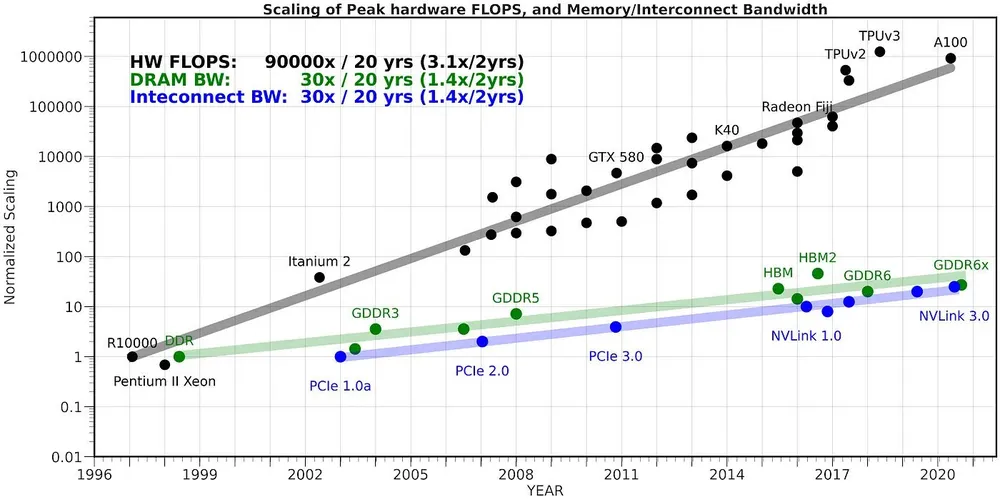
这揭示了芯片发展的更大问题:过去 20 年里,峰值算力 FLOPS 增加了 90000 倍,而 DRAM 互连带宽只增加了 30 倍。内存,尤其是芯片内内存的传输,是训练大模型最重要的限制因素。
Elon Musk 在下面回复说,因为数据传输与计算,目前大多数大型 AI 系统都极其低效。特斯拉估算,至少可以实现一个数量级的改进。
很意外他没有直接点出 Dojo,但通过去年和前年的 AI Day 看,Dojo 显然是为解决这个问题而来。
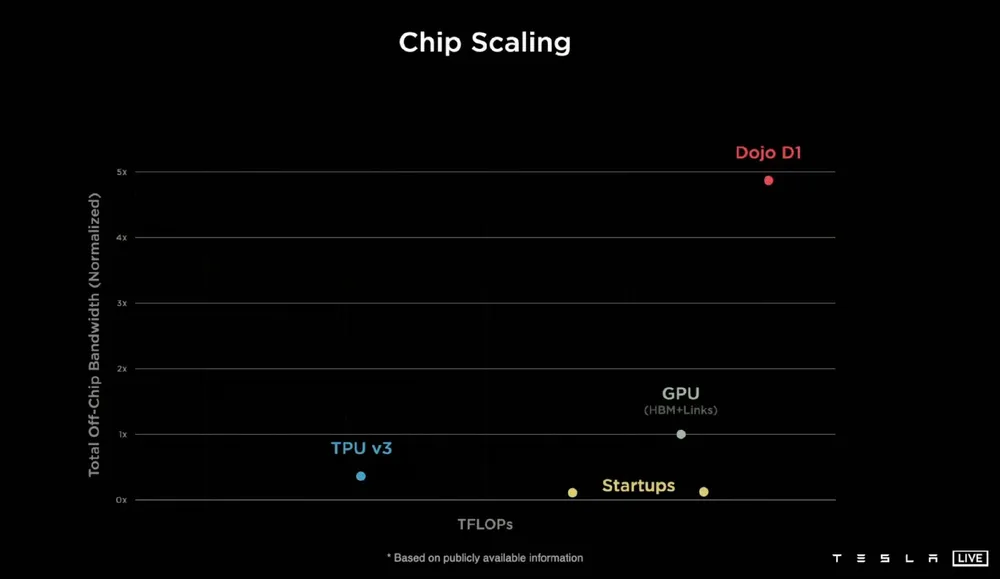
Dojo 的三大性能体现在算力、超高带宽和超低延迟。21 年这张图,横轴是算力,纵轴是带宽,可以看出 Dojo D1 在算力上领先但不太多,带宽是完全鹤立鸡群的,接近英伟达 GPU 5 倍的领先。
Dojo 已经于上个月正式投产。一个基于 Dojo 的 ExaPOD 可以实现 1.1 EFLOP(算力) 、1.3 TB SRAM(延迟)、和 13 TB DRAM(带宽)。
环形隧道
2023-08-16
评论 · 0
0/3
大胆发表你的想法~
相关推荐
不是郑小康
赞
评论
不是郑小康
赞
评论
不是郑小康
赞
评论
不是郑小康
赞
评论
不是郑小康
1
评论
不是郑小康
1
评论
不是郑小康
1
评论
不是郑小康
赞
评论
不是郑小康
赞
评论
不是郑小康
赞
评论
更多



